DataRobot コミュニティ
派生特徴量の naive latest value に関して
- 新着としてマーク
- ブックマーク
- 購読
- ミュート
- RSS フィードを購読する
- ハイライト
- 印刷
- 不適切なコンテンツを報告
04-05-2021
12:44 PM
派生特徴量の naive latest value に関して
(1)
時間認識モデリングにおいて、派生特徴量の「naive latest value」 とは、どのような処理がされた値でしょうか?
「naive latest value」の説明を読むと、rare special events や uncommon events を無視すると記載があるのですが、rare special events や uncommon eventsをどのようなロジックで判定しているでしょうか?
(2)
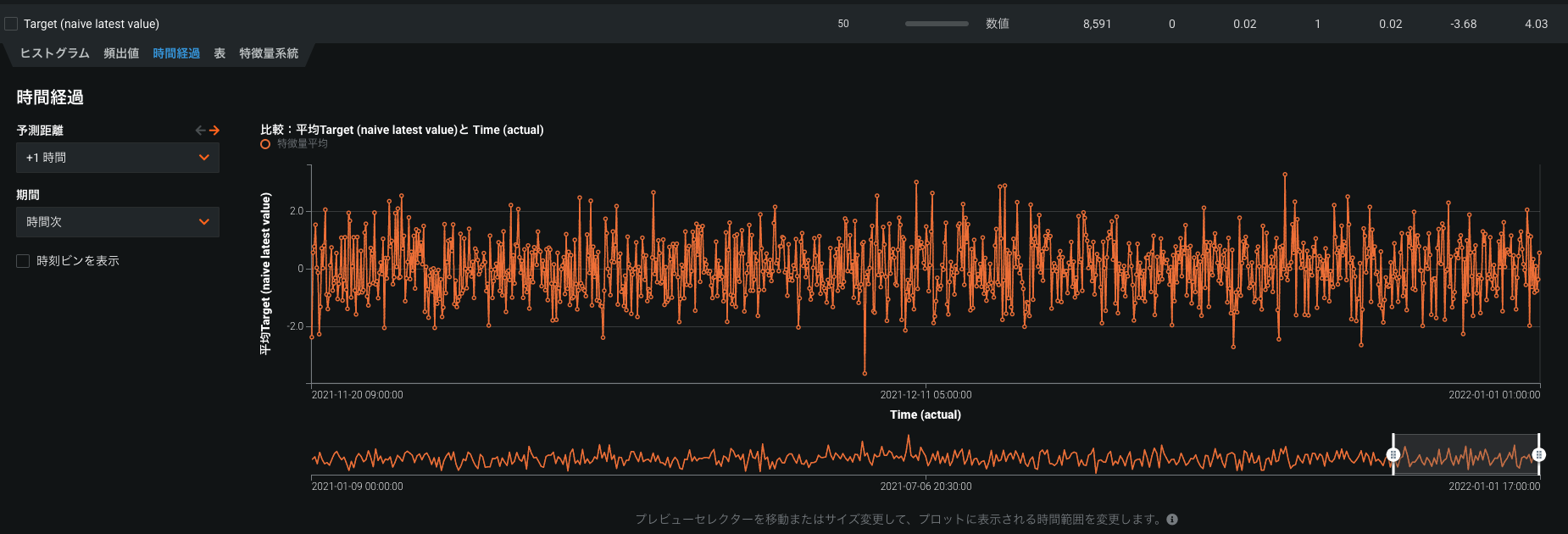
欠測のない1時間ごとの1年間分のデータを学習に利用したところ、モデル学習時に「naive latest value」の文字列がついた特徴量を学習していました。「naive latest value」の文字列が付いた特徴量を、[時間経過]の時系列グラフで[時間次]の期間で確認したところ、多数の時間帯に対して欠測値フラグがついており、サンプリングのような処理がされているように見えています。
時間経過のグラフで表示されているのは、rare special events や uncommon eventsのデータ削除後に残ったデータでしょうか?
(Actual)の文字列が付いた特徴量を[時間経過]の時系列グラフで[時間次]の期間で確認すると、「naive latest value」の特徴量と同様に多数の時間帯に対して欠測値フラグがついているのですが、グラフの見え方の問題でしょうか?それとも、(Actual)に対してもサンプリングのような処理がされているでしょうか?
なお、予測モデルの構築において、ダウンサンプリングの設定はしておらず、
デフォルトから変更したのは、特徴量の派生ウィンドウ、予測ウィンドウ、時系列パーティション、既知の特徴量のみです。
解決済! 解決策の投稿を見る。
8件の返信8
- 新着としてマーク
- ブックマーク
- 購読
- ミュート
- RSS フィードを購読する
- ハイライト
- 印刷
- 不適切なコンテンツを報告
04-08-2021
11:32 PM
ご質問ありがとうございます。DataRobotの佐藤です。
質問に回答させていただきます。
(1)
時間認識モデリングにおいて、派生特徴量の「naive latest value」 とは、どのような処理がされた値でしょうか?
「naive latest value」の説明を読むと、rare special events や uncommon events を無視すると記載があるのですが、rare special events や uncommon eventsをどのようなロジックで判定しているでしょうか?
A.naive latest valueは欠損を除く、過去実績で最も近い値のことを指している特徴量です。欠損がなければ 1th lagと全く同じ意味になります。また、ここで扱われているuncommon events等はそれ自身を検知しているわけではなく、通常のデータ構造から逸脱したケースを除くという意味になります。例えばWeeklyで月曜から金曜日がデータとして通常持たれているケースにおいて、土曜日の値などはuncommon eventsという扱いになり、今回のケースでは無視するという意味です。
(2)
欠測のない1時間ごとの1年間分のデータを学習に利用したところ、モデル学習時に「naive latest value」の文字列がついた特徴量を学習していました。「naive latest value」の文字列が付いた特徴量を、[時間経過]の時系列グラフで[時間次]の期間で確認したところ、多数の時間帯に対して欠測値フラグがついており、サンプリングのような処理がされているように見えています。
時間経過のグラフで表示されているのは、rare special events や uncommon eventsのデータ削除後に残ったデータでしょうか?
(Actual)の文字列が付いた特徴量を[時間経過]の時系列グラフで[時間次]の期間で確認すると、「naive latest value」の特徴量と同様に多数の時間帯に対して欠測値フラグがついているのですが、グラフの見え方の問題でしょうか?それとも、(Actual)に対してもサンプリングのような処理がされているでしょうか?
なお、予測モデルの構築において、ダウンサンプリングの設定はしておらず、
デフォルトから変更したのは、特徴量の派生ウィンドウ、予測ウィンドウ、時系列パーティション、既知の特徴量のみです。
A.こちらなのですが、どのようなポイントについて欠損値のフラグが立っているのでしょうか?
欠損値のフラグに一定の法則があれば、そちらが原因になってくる可能性が高いです。
私の方でも1年間のデータ(1時間毎)を仮に作成し、naive latest valueの特徴量の時間変化を確認したところ欠損がない場合はご指摘の挙動を示しておりませんでしたので、ご確認させていただければと思います。
- 新着としてマーク
- ブックマーク
- 購読
- ミュート
- RSS フィードを購読する
- ハイライト
- 印刷
- 不適切なコンテンツを報告
04-09-2021
11:51 AM
佐藤様
ご回答ありがとうございます。
(1)について、承知いたしました。
(2) に関しては、ご質問に至った画像を添付させて頂きました。
[原系列の時系列データ] 原系列は7日間の移動平均です。

[原系列の(log)(native latest value)の時系列データ]

原系列は7日間の移動平均の特徴量となりますが、
(log)(naive latest value)の時系列データにおいては、一定の間隔で欠測がでているというわけではないです。
時系列グラフにプロットされている日時の一部を順番にピックアップしますと以下となり、曜日や時間によって規則的に欠測値しているというわけではないようにみえております。
9/13 11:00 (木)⇒ 9/14 01:00(金)⇒ 9/18 05:00(火)⇒ 9/18 10:00(火)・・・・
時系列の順番の中で、近しい値が欠測として扱われているようにみえたのですが、疑問に思い質問させて頂きました。
- 新着としてマーク
- ブックマーク
- 購読
- ミュート
- RSS フィードを購読する
- ハイライト
- 印刷
- 不適切なコンテンツを報告
04-10-2021
12:19 AM
こちら、確認させていただいたところ以下のようにいくつかのポイントでデータが前後している部分があるように見受けられるのですが、今一度データの確認をしていただくことは可能でしょうか?

{kind=link}
- 新着としてマーク
- ブックマーク
- 購読
- ミュート
- RSS フィードを購読する
- ハイライト
- 印刷
- 不適切なコンテンツを報告
04-14-2021
12:30 AM
原系列(7日間の移動平均)に対し、日付でsortを実施し、日付の順番を確認しましたが、原系列には日付の順番が前後しているポイントはないです。
日付が前後しているポイントがあるのは、DataRobotが変換した(log)(naive latest value) のデータなのですが、なぜなのでしょうか?
質問を1点追加させて頂きます。1時間間隔のデータ1年分を利用してSARIMAなどの計算量の多いモデルを構築しようとすると、メモリエラーが発生するのですが、1時間間隔のデータを扱う上で、適度なデータ量や制限などありますでしょうか?
- 新着としてマーク
- ブックマーク
- 購読
- ミュート
- RSS フィードを購読する
- ハイライト
- 印刷
- 不適切なコンテンツを報告
04-22-2021
05:37 PM
データの詳細を確認させていただきたく、個別メッセージを送らせていただきました。
- 新着としてマーク
- ブックマーク
- 購読
- ミュート
- RSS フィードを購読する
- ハイライト
- 印刷
- 不適切なコンテンツを報告
04-28-2021
05:08 PM
hiwai様
ご質問ありがとうございます。DataRobotの佐藤です。
こちら、ご共有いただいたデータで調査させていただいたところ、データの前後に関してはUI上のバグでしたので、こちらは再度プロジェクトを作成し、モデリングしていただくと解消いただけるかと思います。
また、欠損に関してですがEDAの際にDataRobot上では特徴量エンジニアリング後のデータが500MBを超える場合に関してはランダムでのダウンサンプリングが行われておりますので、そちらの影響で欠損が発生しているように見える形になります。
モデリング作成時には全てのデータを利用しているので、この部分はモデリングの結果に対して影響を及ぼすことはございません。
追加のご質問に対してですが、通常アップロードができた場合は実行可能かと思いますので、メモリエラーが発生しているケースをご共有いただいてもよろしいでしょうか?
- 新着としてマーク
- ブックマーク
- 購読
- ミュート
- RSS フィードを購読する
- ハイライト
- 印刷
- 不適切なコンテンツを報告
04-28-2021
08:12 PM
ご共有いただき、ありがとうございました。
メモリエラーに関しては製品のバグの一種だと思われますので、大変申し訳ありませんが修正まで今しばらくお待ちいただければと存じます。
- 新着としてマーク
- ブックマーク
- 購読
- ミュート
- RSS フィードを購読する
- ハイライト
- 印刷
- 不適切なコンテンツを報告
05-06-2021
03:09 PM
ご質問いただいていたARIMAのメモリエラーについて調査させていただきました。
現在の仕様ではSeasonal ARIMAに関しては周期性や行数が多いケースにおいては非常に多くのメモリを消費するのでその際に発生するメモリエラーだとおもわれます。
この問題に対する現状可能なアプローチは2つあります。
1.行数が10,000以上の場合はSeasonal ARIMAを利用しない。
2.行数を減らして計算可能なデータ量に合わせる。
今後Seasonal ARIMAを特定のデータ量を超えた場合利用できなくするか、警告を出すか等社内のプロダクトチームと議論を重ねながら決めていきたいと存じます。
大変有益なご質問をいただきありがとうございました。